
Metode analisis Text Mining yang digunakan dalam tulisan ini hanya melibatkan analisis-analisis yang pernah penulis gunakan dalam karya-karya ilmiah yang pernah penulis buat, yakni meliputi clustering, plotting, wordcloud, kata-kata yang sering muncul, dan asosiasi kata.
Data teks yang digunakan dalam analisis ini adalah data tweets dari Twitter. Okay, let's check it out...!
Sebelum melakukan analisis Text Mining dengan R, install dahulu packages yang diperlukan. Adapun packages yang diperlukan adalah httr, twitteR, base64enc, tm, ggplot2, dan wordcloud.
Cara instalasi packages adalah dengan dengan menuliskan sintak berikut.
install.packages("httr","twitteR","base64enc","tm","wordcloud","ggplot2")
Jika cara tersebut tidak berhasil atau terjadi error, Anda dapat mengunduh langsung paket-paket tersebut di https://cran.r-project.org/ atau tanya langsung ke Si Mbah, maksud saya...Si Mbah Google.
Selanjutnya, panggil paketnya dengan menjalankan skrip berikut.
library(twitteR)
library(base64enc)
library(tm)
library(wordcloud)
library(ggplot2)
Kemudian lakukan autentikasi ke Twitter API. Skrip autentikasi ini pernah berubah sebelumnya menjadi skrip yang sekarang penulis gunakan. Skrip ini masih saya gunakan terakhir pada tanggal 16 Januari 2016, tepatnya ketika menulis artikel ini. Skripnya sebagai berikut.
# autentikasi TwitterAPI (sederhananya, izin akses data twitter)
setup_twitter_oauth("Cunsemer Key Anda",
"Consumer Secret Anda",
access_token="Access Token Anda",
access_secret="Access Token Secret Anda")
Selanjutnya, setelah Anda menjalankan skrip di atas, akan muncul tampilan berikut.
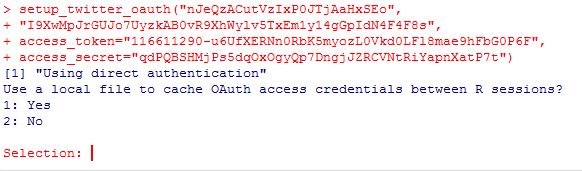
Tulis angka 1 untuk mengisi "Selection" kemudian tekan Enter.
Jika belum memiliki Consumer Key, Consumer Secret, Access Token, dan Access Token Secret, Anda dapat mengunjungi halaman How to Get Keys and Access Token for Twitter API dalam blog ini untuk cara mendapatkannya.
Selanjutnya adalah mengambil data dari twitter sebanyak 200 data dengan kata kunci "wisata yogyakarta"
tweets = searchTwitter("wisata yogyakarta", n=200, lang=NULL)
text = sapply(tweets, function(x) x$getText())
Selanjutnya copas saja skrip berikut untuk analisisnya.
dim(tweets.df)
## [1] 320 14
for(i in c(1:2,320)) {
cat(paste0("[", i,"] "))
writeLines(strwrap(tweets.df$text[i],60))
}
# build a corpus, and specify the source to be character vectors
myCorpus<-Corpus(VectorSource(tweets.df$text))
# hanya mengambil huruf dan spasi
removeNumPunct<-function(x)gsub("[^[:alpha:][:space:]]*","", x)
myCorpus<-tm_map(myCorpus,content_transformer(removeNumPunct))
# remove URLs
removeURL<-function(x)gsub("http[^[:space:]]*","", x)
myCorpus<-tm_map(myCorpus,content_transformer(removeURL))
# remove punctuation
myCorpus <- tm_map(myCorpus, removePunctuation)
# remove numbers
myCorpus <- tm_map(myCorpus, removeNumbers)
# remove URLs
removeURL<-function(x)gsub("http[^[:space:]]*","", x)
myCorpus<-tm_map(myCorpus,content_transformer(removeURL))
# convert to lower case
myCorpus<-tm_map(myCorpus,content_transformer(tolower))
# add two extra stop words: "available" and "via"
myStopwords<-c(stopwords('english'),"dan","itu","saya","kamu","acara","akan","yang","http","https")
# remove stopwords from corpus
myCorpus<-tm_map(myCorpus, removeWords, myStopwords)
# remove extra whitespace
myCorpus<-tm_map(myCorpus, stripWhitespace)
myCorpusCopy<-myCorpus
# stem words
myCorpus<-tm_map(myCorpus, stemDocument)
for(i in c(1:2,320)) {
cat(paste0("[", i,"] "))
writeLines(strwrap(as.character(myCorpus[[i]]),60))
}
stemCompletion2<-function(x,dictionary) {
x<-unlist(strsplit(as.character(x)," "))
# Unexpectedly, stemCompletion completes an empty string to
# a word in dictionary. Remove empty string to avoid above issue.
x<-x[x!=""]
x<-stemCompletion(x,dictionary=dictionary)
x<-paste(x,sep="",collapse=" ")
PlainTextDocument(stripWhitespace(x))
}
myCorpus<-lapply(myCorpus, stemCompletion2,dictionary=myCorpusCopy)
myCorpus<-Corpus(VectorSource(myCorpus))
miningCases<-lapply(myCorpusCopy,
function(x) { grep(as.character(x),pattern=" \\<mining")} )
sum(unlist(miningCases))
minerCases<-lapply(myCorpusCopy,
function(x) {grep(as.character(x),pattern=" \\<miner")} )
sum(unlist(minerCases))
#mengganti kata "keindahan" dengan "indah", "kenalkan" dengan "kenal"
myCorpus<-tm_map(myCorpus,content_transformer(gsub),pattern="keindahan",replacement="indah")
myCorpus<-tm_map(myCorpus,content_transformer(gsub),pattern="kenalkan",replacement="kenal")
control=list(wordLengths=c(1,Inf)))
tdm
idx<-which(dimnames(tdm)$Terms=="wisata")
inspect(tdm[idx+(0:5),101:110])
(freq.terms<-findFreqTerms(tdm,lowfreq=100))
term.freq<-rowSums(as.matrix(tdm))
term.freq<-subset(term.freq, term.freq>=100)
df<-data.frame(term=names(term.freq),freq= term.freq)
library(ggplot2)
ggplot(df,aes(x=term,y=freq))+geom_bar(stat="identity")+
xlab("Terms")+ylab("Count")+coord_flip()
# barplot kata
barplot(termFrequency, las=2)
#Frequent Terms and Associations (kata yang sering keluar dan asosiasi kata)
findFreqTerms(tdm, lowfreq=100)
findAssocs(tdm, 'yogyakarta', 0.3)
# clustering
# menghapus istilah/kata yang jarang
tdm2<-removeSparseTerms(tdm,sparse=0.95)
m2<-as.matrix(tdm2)
# cluster terms
distMatrix<-dist(scale(m2))
fit<-hclust(distMatrix,method="ward")
plot(fit)
rect.hclust(fit,k=3)
m<-as.matrix(tdm)
# menghitung frekuensi kata dan mengurutkannya
word.freq<-sort(rowSums(m),decreasing= T)
# colors
pal<-brewer.pal(9,"BuGn")
pal<-pal[-(1:4)]
# membuat awan kata (word cloud)
library(wordcloud)
wordcloud(words=names(word.freq),freq=word.freq,min.freq=50,
random.order= F,colors= pal)
Output analisis dibahas di sini.
Thanks for reading Text Mining (Twitter Analysis) in R
ReplyDeleteGreat Article
R Project Topics for Computer Science
FInal Year Project Centers in Chennai
JavaScript Training in Chennai
JavaScript Training in Chennai
Thanks a lot for posting this, it is very informative . A Turkish visa online is nothing more than a substitute for a Turkish physical visa. but the application process is more simple than the Turkish physical visa. You can also read all the points about the Turkish online visa.
ReplyDeleteMmorpg
ReplyDeleteinstagram takipçi satın al
tiktok jeton hilesi
tiktok jeton hilesi
antalya saç ekimi
referans kimliği nedir
İnstagram Takipçi Satın Al
Takipci satin al
metin2 pvp serverlar
TÜL PERDE MODELLERİ
ReplyDeletesms onay
mobil ödeme bozdurma
nft nasıl alınır
ankara evden eve nakliyat
trafik sigortası
dedektör
WEBSİTESİ KURMAK
aşk kitapları
çekmeköy daikin klima servisi
ReplyDeleteataşehir daikin klima servisi
maltepe toshiba klima servisi
kadıköy toshiba klima servisi
maltepe beko klima servisi
kadıköy beko klima servisi
beykoz samsung klima servisi
üsküdar samsung klima servisi
beykoz mitsubishi klima servisi