Terdapat suatu aktivitas dalam statistika yang menjadi penghubung antara statistika dengan ilmu hukum, yaitu uji hipotesis statistik. Uji hipotesis statistik berkait-kelindan dengan proses pengambilan keputusan di meja hijau. Penolakan atau penerimaan suatu hipotesis statistik memiliki prinsip yang serupa dengan putusan seorang hakim dalam suatu sidang perkara pidana mengenai apakah si terdakwa divonis bersalah atau tidak.
Prinsip yang digunakan dalam pengujian hipotesis sebenarnya adalah prinsip yang seringkali diterapkan dalam kehidupan sehari-hari. Mulai dari mengamati kondisi atau gejala, menyatakan dugaan, mencari bukti, sampai menetapkan kesimpulan. Misalnya, seseorang mendapati dirinya mengalami batuk yang tidak kunjung sembuh selama berminggu-minggu. Meskipun telah mengonsumsi obat batuk, namun tetap tidak memberikan pengaruh yang berarti. Di kemudian hari, bahkan ia mengeluarkan darah yang keluar dari tenggorokannya disertai batuk.
Ia kemudian melaporkan apa yang dialaminya kepada seorang dokter. Sebagai pasien, ia menceritakan apa yang dialaminya kepada dokter tersebut. Berdasarkan gejala-gejala yang diutarakan oleh pasien, dokter tersebut kemudian membuat dugaan mengenai kemungkinan penyakit yang diderita orang tersebut, yaitu bahwa pasien tersebut menderita penyakit TBC. Agar memperkuat dugaan tersebut, dokter kemudian menganjurkan suatu pemeriksaan di laboratorium untuk menguji sampel darah, dahak, air seni, dan feses pasien. Dari hasil pemeriksaan di laboratorium, kemudian dokter menyimpulkan penyakit apa yang diderita oleh pasien. Sebagai catatan, tidak menutup kemungkinan dokter melakukan kesalahan dalam mendiagnosis penyakit pasien.
Setelah melakukan uji laboratorium, diperoleh hasil bahwa pengujian sampel darah, dahak, air seni, dan feses pasien menunjukkan adanya bakteri penyebab TBC, yaitu micobacterium tuberculosa, dalam tubuh pasien. Dengan kata lain, pasien positif mengidap TBC. Sehingga, dokter menyimpulkan bahwa dugannya terbukti, diperkuat dengan hasil uji laboratorium tersebut. Pasien kemudian didiagnosis mengidap penyakit TBC dan diberi perlakuan layaknya penderita penyakit TBC.
Pengambilan kesimpulan oleh dokter dalam mendiagnosis suatu penyakit merupakan contoh dari prinsip pengambilan kesimpulan berdasarkan hasil pengamatan terhadap data untuk memperkuat dugaan dalam ranah ilmu medis. Dokter tidak serta merta mendiagnosis suatu penyakit, melainkan karena terdapat bukti yang cukup untuk menyimpulkan penyakit yang diderita oleh pasien.
Prinsip yang sama digunakan oleh seorang hakim di meja hijau. Dalam ranah ilmu hukum, khususnya hukum acara pidana yang berlaku di Indonesia, seorang hakim tidak dapat menjatuhkan hukuman pidana kepada seorang terdakwa sampai terdapat bukti atau kesaksian saksi yang meyakinkan bahwa terdakwa benar-benar bersalah.
Sebagai contoh, misalkan di suatu kafe terdapat kasus pembunuhan yang tersembunyi menggunakan racun yang dimasukkan ke dalam kopi yang diminum oleh korban. Berdasarkan keterangan dari pelayan kafe dan rekaman CCTV, muncul dugaan terhadap salah seorang tersangka tindak pidana pembunuhan. Singkat cerita, tersangka tersebut akhirnya ditetapkan sebagai terdakwa dan harus mendatangi sidang di pengadilan.
Dalam persidangan ini, seorang hakim memiliki praduga tak bersalah kepada terdakwa, karena belum ada bukti yang cukup untuk menyatakan bahwa terdakwa benar-benar melakukan pembunuhan. Menurut Pasal 183 KUHAP, “Hakim tidak boleh menjatuhkan pidana kepada seseorang, kecuali apabila dengan sekurang-kurangnya dua alat bukti yang sah ia memperoleh keyakinan bahwa suatu tindak pidana benar-benar terjadi dan bahwa terdakwalah yang bersalah melakukannya.”
Seorang hakim tidak serta-merta memvonis bahwa terdakwa bersalah, karena terdakwa tersebut baru diduga melakukan suatu tindak pidana, yaitu pembunuhan. Dugaan tersebut tidak dapat dijadikan landasan untuk mengambil keputusan tanpa adanya bukti yang mencukupi. Oleh karena itu, untuk membuktikan dugaan tersebut, hakim menanyai saksi-saksi dan meminta alat-alat bukti yang lain diajukan atau ditunjukkan di persidangan hingga batas minimum pembuktian dicapai.
Dari alat-alat bukti tersebut, pada akhirnya hakim akan menentukan apakah terdakwa tersebut dijatuhi hukuman, atau terdakwa tersebut bebas (vrij spraak) atau lepas dari segala tuntutan hukum (onslag van recht vervolging), atau penetapan tidak berwenang mengadili, atau putusan yang menyatakan dakwaan tidak dapat diterima, atau putusan yang menyatakan dakwaan batal demi hukum[i]. Perlu menjadi catatan juga bahwa vonis hakim yang dikeluarkan di persidangan tidak terlepas dari kemungkinan keliru atau salah dalam menyimpulkan. Dengan kata lain, putusan hakim tersebut adalah dugaan kuat yang didasarkan pada bukti-bukti dan kesaksian para saksi, bukan merupakan keyakinan sempurna (100%) karena hakim tidak melihat langsung terdakwa melakukan tindak pidana tersebut.
Berdasarkan pernyataan saksi dan bukti yang dihadirkan di persidangan, akhirnya hakim memutuskan bahwa terdakwa tidak bersalah. Hal ini disebabkan tidak cukup bukti yang kuat untuk menyatakan bahwa terdakwa melakukan tindak pidana pembunuhan sebagaiamana dituduhkan oleh jaksa.
Keputusan bahwa terdakwa dibebaskan bukan berarti terdakwa tidak melakukan tindak pidana pembunuhan, melainkan karena bukti yang didapatkan tidak mencukupi untuk mendukung vonis bersalah. Seorang hakim mungkin saja melakukan kesalahan dalam menyimpulkan. Meskipun pada kenyataannya terdakwa benar-benar melakukan pembunuhan, tetapi bukti yang dihadirkan di pengadilan tidak dianggap cukup untuk menetapkan vonis bersalah, maka hakim tersebut tidak menetapkan vonis bersalah kepada terdakwa.
Dari uraian tersebut, dapat dipahami bahwa paling tidak terdapat empat langkah yang dijalani dalam proses penetapan keputusan dan kesimpulan. Pertama, mengamati kondisi atau gejala yang terjadi. Pada kasus pertama, yaitu kasus di bidang medis, seseorang mengalami kondisi atau gejala batuk yang berkepanjangan disertai darah. Pada kasus kedua, yakni kasus hukum, kondisi yang terjadi adalah pembunuhan di suatu kafe.
Kedua kondisi ini merupakan masalah yang membutuhkan suatu pemecahan berupa jawaban atau kesimpulan. Pada kasus medis, kondisi pasien membutuhkan kesimpulan tentang penyakit apa yang diderita. Pada kasus hukum, kondisi kejadian pembunuhan membutuhkan kesimpulan tentang siapakah yang menjadi terpidana pembunuhan tersebut, apakah tersangka benar-benar melakukan tindak pidana atau tidak.
Kedua, menyatakan dugaan kuat. Dugaan yang dinyatakan berdasarkan gejala atau kondisi awal disebut dengan hipotesis. Hipotesis ini bersifat tentatif atau sementara karena belum diperkuat dengan bukti yang memadai. Pada kasus medis, seorang dokter menduga bahwa penyakit yang diderita pasien adalah TBC berdasarkan gejala yang timbul dari pasien. Pada kasus hukum, seorang hakim menduga bahwa terdakwa tersebut adalah pelakunya berdasarkan laporan kepolisian dan tuntutan jaksa. Jika tidak diduga bersalah, maka tidak mungkin jadi tersangka apalagi terdakwa.
Ketiga, mencari bukti dan data. Seseorang tidak dibenarkan membuat kesimpulan berlandaskan dugaan yang tidak berdasar. Oleh karena itu, data yang diperoleh dari hasil observasi diperlukan sebagai bukti untuk mendukung dugaan. Pada kasus pertama, sampel darah dan dahak diambil dari pasien untuk diuji di laboratorium. Hasil dari tes laboratorium tersebut dijadikan landasan oleh dokter dalam diagnosis penyakit yang diderita oleh pasien. Pada kasus kedua, saksi-saksi diperiksa dan diminta kesaksiannya serta alat-alat bukti diajukan di persidangan sebagai landasan bagi hakim dalam menetapkan keputusan.
Keempat, menetapkan keputusan dan kesimpulan. Penetapan keputusan dan kesimpulan ini didasarkan pada data dan bukti yang sedapat mungkin dikumpulkan. Pada kasus medis, seorang dokter menyimpulkan bahwa pasien benar-benar menderita penyakit TBC berdasarkan hasil pengujian sampel darah, dahak, air seni, dan feses pasien di laboratorium, yang mana hasil pengujian tersebut menyatakan bahwa pasien benar-benar menderita penyakit TBC. Pada kasus hukum, meskipun bukti telah dihadirkan dan saksi telah memberi pernyataan, tetapi tidak cukup bagi hakim untuk menyatakan bahwa terdakwa bersalah telah melakukan pembunuhan, meskipun bisa saja pada kenyataannya terdakwa itu benar-benar melakukan tindak pidana pembunuhan.
Uji hipotesis dalam disiplin ilmu statistik pun dilakukan dengan langkah-langkah yang serupa. Bermula dari suatu kondisi atau gejala yang menimbulkan permasalahan, kemudian muncul hipotesis atau dugaan, lantas dilakukan pengamatan/observasi/penelitian untuk mencari data pendukung hipotesis tersebut, dan berakhir dengan penarikan kesimpulan apakah hipotesis tersebut ditolak atau diterima dengan tingkat keyakinan tertentu.
Sebagai contoh, seorang dosen merasa bahwa perlu adanya metode pembelajaran yang baru untuk meningkatkan nilai mahasiswa dalam suatu mata kuliah yang diampunya. Setelah ia menemukan suatu metode pembelajaran yang baru, ia kemudian ingin mengetahui apakah metode pembelajaran yang ia temukan memberikan pengaruh yang signifikan terhadap nilai mata kuliah yang diampunya (mengamati kondisi).
Dosen tersebut kemudian mulai menerapkan metode pembelajaran baru tersebut. Ia menduga bahwa metode pembelajaran baru itu berpengaruh secara efektif terhadap kenaikan nilai mahasiswa dalam mata kuliah tersebut (muncul hipotesis atau dugaan).
Untuk membuktikan dugaan tersebut, dosen itu melakukan penelitian terhadap nilai mahasiswa dalam mata kuliah yang diampunya. Ia mengambil nilai dari sebagian mahasiswa (sebagai sampel) sebelum metode pembelajaran baru diterapkan dan setelah metode pembelajaran baru diterapkan (mengumpulkan data).
Kedua kelompok sampel nilai ini kemudian dibandingkan, apakah terdapat perbedaan yang signifikan di antara keduanya atau tidak. Setelah dianalisis, ternyata terdapat perbedaan yang signifikan antara nilai mahasiswa sebelum dan sesudah diterapkan metode pembelajaran yang baru. Nilai mahasiswa setelah pembaruan metode pembelajaran lebih besar dibandingkan sebelum pembaruan metode pembelajaran. Sang dosen lantas menyimpulkan bahwa metode pembelajaran baru yang ia gagas memberikan pengaruh yang signifikan terhadap kenaikan nilai mahasiswa dalam mata kuliah yang diampunya (penarikan kesimpulan).
[i] Edscyclopedia.com, Ketika Ilmu Hukum Seiring Statistika, http://edscyclopedia.com/ketika-ilmu-hukum-seiring-statistika/, diakses pada tanggal 13 September 2016.
Prinsip yang digunakan dalam pengujian hipotesis sebenarnya adalah prinsip yang seringkali diterapkan dalam kehidupan sehari-hari. Mulai dari mengamati kondisi atau gejala, menyatakan dugaan, mencari bukti, sampai menetapkan kesimpulan. Misalnya, seseorang mendapati dirinya mengalami batuk yang tidak kunjung sembuh selama berminggu-minggu. Meskipun telah mengonsumsi obat batuk, namun tetap tidak memberikan pengaruh yang berarti. Di kemudian hari, bahkan ia mengeluarkan darah yang keluar dari tenggorokannya disertai batuk.
Ia kemudian melaporkan apa yang dialaminya kepada seorang dokter. Sebagai pasien, ia menceritakan apa yang dialaminya kepada dokter tersebut. Berdasarkan gejala-gejala yang diutarakan oleh pasien, dokter tersebut kemudian membuat dugaan mengenai kemungkinan penyakit yang diderita orang tersebut, yaitu bahwa pasien tersebut menderita penyakit TBC. Agar memperkuat dugaan tersebut, dokter kemudian menganjurkan suatu pemeriksaan di laboratorium untuk menguji sampel darah, dahak, air seni, dan feses pasien. Dari hasil pemeriksaan di laboratorium, kemudian dokter menyimpulkan penyakit apa yang diderita oleh pasien. Sebagai catatan, tidak menutup kemungkinan dokter melakukan kesalahan dalam mendiagnosis penyakit pasien.
Setelah melakukan uji laboratorium, diperoleh hasil bahwa pengujian sampel darah, dahak, air seni, dan feses pasien menunjukkan adanya bakteri penyebab TBC, yaitu micobacterium tuberculosa, dalam tubuh pasien. Dengan kata lain, pasien positif mengidap TBC. Sehingga, dokter menyimpulkan bahwa dugannya terbukti, diperkuat dengan hasil uji laboratorium tersebut. Pasien kemudian didiagnosis mengidap penyakit TBC dan diberi perlakuan layaknya penderita penyakit TBC.
Pengambilan kesimpulan oleh dokter dalam mendiagnosis suatu penyakit merupakan contoh dari prinsip pengambilan kesimpulan berdasarkan hasil pengamatan terhadap data untuk memperkuat dugaan dalam ranah ilmu medis. Dokter tidak serta merta mendiagnosis suatu penyakit, melainkan karena terdapat bukti yang cukup untuk menyimpulkan penyakit yang diderita oleh pasien.
Prinsip yang sama digunakan oleh seorang hakim di meja hijau. Dalam ranah ilmu hukum, khususnya hukum acara pidana yang berlaku di Indonesia, seorang hakim tidak dapat menjatuhkan hukuman pidana kepada seorang terdakwa sampai terdapat bukti atau kesaksian saksi yang meyakinkan bahwa terdakwa benar-benar bersalah.
Sebagai contoh, misalkan di suatu kafe terdapat kasus pembunuhan yang tersembunyi menggunakan racun yang dimasukkan ke dalam kopi yang diminum oleh korban. Berdasarkan keterangan dari pelayan kafe dan rekaman CCTV, muncul dugaan terhadap salah seorang tersangka tindak pidana pembunuhan. Singkat cerita, tersangka tersebut akhirnya ditetapkan sebagai terdakwa dan harus mendatangi sidang di pengadilan.
Dalam persidangan ini, seorang hakim memiliki praduga tak bersalah kepada terdakwa, karena belum ada bukti yang cukup untuk menyatakan bahwa terdakwa benar-benar melakukan pembunuhan. Menurut Pasal 183 KUHAP, “Hakim tidak boleh menjatuhkan pidana kepada seseorang, kecuali apabila dengan sekurang-kurangnya dua alat bukti yang sah ia memperoleh keyakinan bahwa suatu tindak pidana benar-benar terjadi dan bahwa terdakwalah yang bersalah melakukannya.”
Seorang hakim tidak serta-merta memvonis bahwa terdakwa bersalah, karena terdakwa tersebut baru diduga melakukan suatu tindak pidana, yaitu pembunuhan. Dugaan tersebut tidak dapat dijadikan landasan untuk mengambil keputusan tanpa adanya bukti yang mencukupi. Oleh karena itu, untuk membuktikan dugaan tersebut, hakim menanyai saksi-saksi dan meminta alat-alat bukti yang lain diajukan atau ditunjukkan di persidangan hingga batas minimum pembuktian dicapai.
Dari alat-alat bukti tersebut, pada akhirnya hakim akan menentukan apakah terdakwa tersebut dijatuhi hukuman, atau terdakwa tersebut bebas (vrij spraak) atau lepas dari segala tuntutan hukum (onslag van recht vervolging), atau penetapan tidak berwenang mengadili, atau putusan yang menyatakan dakwaan tidak dapat diterima, atau putusan yang menyatakan dakwaan batal demi hukum[i]. Perlu menjadi catatan juga bahwa vonis hakim yang dikeluarkan di persidangan tidak terlepas dari kemungkinan keliru atau salah dalam menyimpulkan. Dengan kata lain, putusan hakim tersebut adalah dugaan kuat yang didasarkan pada bukti-bukti dan kesaksian para saksi, bukan merupakan keyakinan sempurna (100%) karena hakim tidak melihat langsung terdakwa melakukan tindak pidana tersebut.
Berdasarkan pernyataan saksi dan bukti yang dihadirkan di persidangan, akhirnya hakim memutuskan bahwa terdakwa tidak bersalah. Hal ini disebabkan tidak cukup bukti yang kuat untuk menyatakan bahwa terdakwa melakukan tindak pidana pembunuhan sebagaiamana dituduhkan oleh jaksa.
Keputusan bahwa terdakwa dibebaskan bukan berarti terdakwa tidak melakukan tindak pidana pembunuhan, melainkan karena bukti yang didapatkan tidak mencukupi untuk mendukung vonis bersalah. Seorang hakim mungkin saja melakukan kesalahan dalam menyimpulkan. Meskipun pada kenyataannya terdakwa benar-benar melakukan pembunuhan, tetapi bukti yang dihadirkan di pengadilan tidak dianggap cukup untuk menetapkan vonis bersalah, maka hakim tersebut tidak menetapkan vonis bersalah kepada terdakwa.
Dari uraian tersebut, dapat dipahami bahwa paling tidak terdapat empat langkah yang dijalani dalam proses penetapan keputusan dan kesimpulan. Pertama, mengamati kondisi atau gejala yang terjadi. Pada kasus pertama, yaitu kasus di bidang medis, seseorang mengalami kondisi atau gejala batuk yang berkepanjangan disertai darah. Pada kasus kedua, yakni kasus hukum, kondisi yang terjadi adalah pembunuhan di suatu kafe.
Kedua kondisi ini merupakan masalah yang membutuhkan suatu pemecahan berupa jawaban atau kesimpulan. Pada kasus medis, kondisi pasien membutuhkan kesimpulan tentang penyakit apa yang diderita. Pada kasus hukum, kondisi kejadian pembunuhan membutuhkan kesimpulan tentang siapakah yang menjadi terpidana pembunuhan tersebut, apakah tersangka benar-benar melakukan tindak pidana atau tidak.
Kedua, menyatakan dugaan kuat. Dugaan yang dinyatakan berdasarkan gejala atau kondisi awal disebut dengan hipotesis. Hipotesis ini bersifat tentatif atau sementara karena belum diperkuat dengan bukti yang memadai. Pada kasus medis, seorang dokter menduga bahwa penyakit yang diderita pasien adalah TBC berdasarkan gejala yang timbul dari pasien. Pada kasus hukum, seorang hakim menduga bahwa terdakwa tersebut adalah pelakunya berdasarkan laporan kepolisian dan tuntutan jaksa. Jika tidak diduga bersalah, maka tidak mungkin jadi tersangka apalagi terdakwa.
Ketiga, mencari bukti dan data. Seseorang tidak dibenarkan membuat kesimpulan berlandaskan dugaan yang tidak berdasar. Oleh karena itu, data yang diperoleh dari hasil observasi diperlukan sebagai bukti untuk mendukung dugaan. Pada kasus pertama, sampel darah dan dahak diambil dari pasien untuk diuji di laboratorium. Hasil dari tes laboratorium tersebut dijadikan landasan oleh dokter dalam diagnosis penyakit yang diderita oleh pasien. Pada kasus kedua, saksi-saksi diperiksa dan diminta kesaksiannya serta alat-alat bukti diajukan di persidangan sebagai landasan bagi hakim dalam menetapkan keputusan.
Keempat, menetapkan keputusan dan kesimpulan. Penetapan keputusan dan kesimpulan ini didasarkan pada data dan bukti yang sedapat mungkin dikumpulkan. Pada kasus medis, seorang dokter menyimpulkan bahwa pasien benar-benar menderita penyakit TBC berdasarkan hasil pengujian sampel darah, dahak, air seni, dan feses pasien di laboratorium, yang mana hasil pengujian tersebut menyatakan bahwa pasien benar-benar menderita penyakit TBC. Pada kasus hukum, meskipun bukti telah dihadirkan dan saksi telah memberi pernyataan, tetapi tidak cukup bagi hakim untuk menyatakan bahwa terdakwa bersalah telah melakukan pembunuhan, meskipun bisa saja pada kenyataannya terdakwa itu benar-benar melakukan tindak pidana pembunuhan.
Uji hipotesis dalam disiplin ilmu statistik pun dilakukan dengan langkah-langkah yang serupa. Bermula dari suatu kondisi atau gejala yang menimbulkan permasalahan, kemudian muncul hipotesis atau dugaan, lantas dilakukan pengamatan/observasi/penelitian untuk mencari data pendukung hipotesis tersebut, dan berakhir dengan penarikan kesimpulan apakah hipotesis tersebut ditolak atau diterima dengan tingkat keyakinan tertentu.
Sebagai contoh, seorang dosen merasa bahwa perlu adanya metode pembelajaran yang baru untuk meningkatkan nilai mahasiswa dalam suatu mata kuliah yang diampunya. Setelah ia menemukan suatu metode pembelajaran yang baru, ia kemudian ingin mengetahui apakah metode pembelajaran yang ia temukan memberikan pengaruh yang signifikan terhadap nilai mata kuliah yang diampunya (mengamati kondisi).
Dosen tersebut kemudian mulai menerapkan metode pembelajaran baru tersebut. Ia menduga bahwa metode pembelajaran baru itu berpengaruh secara efektif terhadap kenaikan nilai mahasiswa dalam mata kuliah tersebut (muncul hipotesis atau dugaan).
Untuk membuktikan dugaan tersebut, dosen itu melakukan penelitian terhadap nilai mahasiswa dalam mata kuliah yang diampunya. Ia mengambil nilai dari sebagian mahasiswa (sebagai sampel) sebelum metode pembelajaran baru diterapkan dan setelah metode pembelajaran baru diterapkan (mengumpulkan data).
Kedua kelompok sampel nilai ini kemudian dibandingkan, apakah terdapat perbedaan yang signifikan di antara keduanya atau tidak. Setelah dianalisis, ternyata terdapat perbedaan yang signifikan antara nilai mahasiswa sebelum dan sesudah diterapkan metode pembelajaran yang baru. Nilai mahasiswa setelah pembaruan metode pembelajaran lebih besar dibandingkan sebelum pembaruan metode pembelajaran. Sang dosen lantas menyimpulkan bahwa metode pembelajaran baru yang ia gagas memberikan pengaruh yang signifikan terhadap kenaikan nilai mahasiswa dalam mata kuliah yang diampunya (penarikan kesimpulan).
[i] Edscyclopedia.com, Ketika Ilmu Hukum Seiring Statistika, http://edscyclopedia.com/ketika-ilmu-hukum-seiring-statistika/, diakses pada tanggal 13 September 2016.


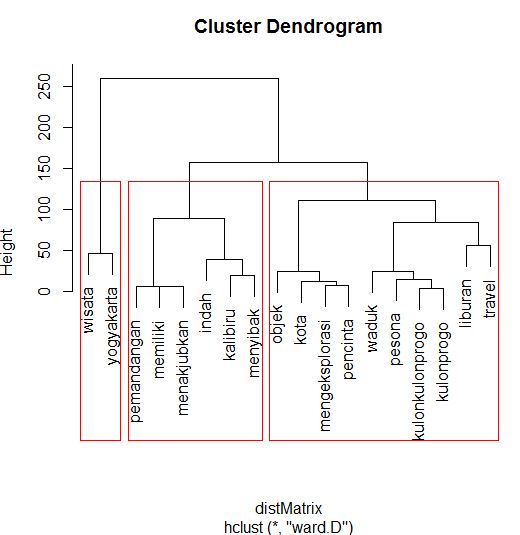
 Outputs in R")